构建要使用的数据集:让我们看看数据库中的前1000部电影¶
使用前面的API我们只获取前50个页面。如前文所说,可以使用 top_movies=all_movies.popular() 的”page”参数实现。
注意:下面的一些代码会在名为 “pickle” 的python文件中存储一些数据用来被内存访问,而不是每次都重新下载。一旦完成,你应该注释掉这些会产生新对象的代码并不再使用。
all_movies=tmdb.Movies()
top_movies=all_movies.popular()
len(top_movies['results'])
top20_movs=top_movies['results']
# 当数据保存到pickle文件后请注释掉这段代码
all_movies=tmdb.Movies()
top1000_movies=[]
print('Pulling movie list, Please wait...')
for i in range(1,51):
if i%15==0:
time.sleep(7)
movies_on_this_page=all_movies.popular(page=i)['results']
top1000_movies.extend(movies_on_this_page)
len(top1000_movies)
f3=open('movie_list.pckl','wb')
pickle.dump(top1000_movies,f3)
f3.close()
print('Done!')
f3=open('movie_list.pckl','rb')
top1000_movies=pickle.load(f3)
f3.close()
结对分析电影类型¶
由于我们的数据集是多标签的,仅仅只是关注类型分类是不充分的。观察哪些类型同时出现可能是有益的,因为它可能有助于揭示我们数据集中的固有偏见。例如,如果浪漫和喜剧比纪录片和喜剧更经常地出现在一起,那是有意义的。这种固有的偏见告诉我们,我们从自身抽样的潜在人群是不平衡的。然后我们可以采取步骤来考虑这些问题。即使我们不采取这些步骤,重要的是要意识到我们所做的假设是不平衡的数据集不会损害我们的性能,如果需要,我们可以回过头来修正这个假设。古老但有用的科学方法,不是吗?
所以对于前1000部电影,我们来做一些类型分布的结对分析。我们的主要目的是看哪些类型的电影出现在同一部电影中。因此,我们首先定义一个函数,它取一个列表,并从中生成所有可能的对。然后,我们提取电影的类型列表,并在类型列表上运行这个函数,以获得所有同时出现的类型对。
# 此方法生成所有可能的电影组合
def list2pairs(l):
# itertools.combinations(l,2) 从列表l中生成长度为2的组合
pairs = list(itertools.combinations(l, 2))
# 然后是长度为1的组合,重复的组合不会被itertools计算
for i in l:
pairs.append([i,i])
return pairs
如我所说,现在我们要抓取每部电影的类型数据,然后使用上面的方法计算两种类型同时出现的概率
# get all genre lists pairs from all movies
allPairs = []
for movie in top1000_movies:
allPairs.extend(list2pairs(movie['genre_ids']))
nr_ids = np.unique(allPairs)
visGrid = np.zeros((len(nr_ids), len(nr_ids)))
for p in allPairs:
visGrid[np.argwhere(nr_ids==p[0]), np.argwhere(nr_ids==p[1])]+=1
if p[1] != p[0]:
visGrid[np.argwhere(nr_ids==p[1]), np.argwhere(nr_ids==p[0])]+=1
让我们看看刚刚新建的数据结构。这是一个如下所示的19X19的结构。也就是说我们有19中类型,不用说,这种结构计算了同一部电影中同时出现的类型的数量。
print visGrid.shape
print len(Genre_ID_to_name.keys())
(19, 19)
19
annot_lookup = []
for i in xrange(len(nr_ids)):
annot_lookup.append(Genre_ID_to_name[nr_ids[i]])
sns.heatmap(visGrid, xticklabels=annot_lookup, yticklabels=annot_lookup)

上图以热力图的形式展现了经常同时出现的类型的分布
在上面的图中需要注意的重要一点是对角线。对角线对应的是自我对应,即一个类型出现的次数,例如戏剧与戏剧一起出现的次数。这基本上可以认为是一种类型发生的总次数的计数!
我们也可以看到许多数据集中在戏剧类型上,当然这也是一个很通用的类型标签。几乎没有纪录片或者是电视电影出现。恐怖片是一个非常独特的类别,浪漫类型也不是分布很广。
为了了解这些数据不均匀的原因,我们可以尝试多种方式来探索可能发现的一些有趣关系。
深入探索同时出现的类型¶
我们现在要做的是寻找一些同时出现类型的最佳集合,并看看逻辑上对我们是否有用?直观来说,看到上图呈现出正方形聚集不会太意外–大多数分布在正方形区域也就是说某些类型总是同时出现而与其他类型却很少交互。某种意义上说,这将凸显并区分出哪些类型同时出现而哪些不是。
尽管这些数据也许不会直接显示,但我们可以分析一下这些数据。这里用到的技术叫做双聚类分析。
from sklearn.cluster import SpectralCoclustering
model = SpectralCoclustering(n_clusters=5)
model.fit(visGrid)
fit_data = visGrid[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
annot_lookup_sorted = []
for i in np.argsort(model.row_labels_):
annot_lookup_sorted.append(Genre_ID_to_name[nr_ids[i]])
sns.heatmap(fit_data, xticklabels=annot_lookup_sorted, yticklabels=annot_lookup_sorted, annot=False)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
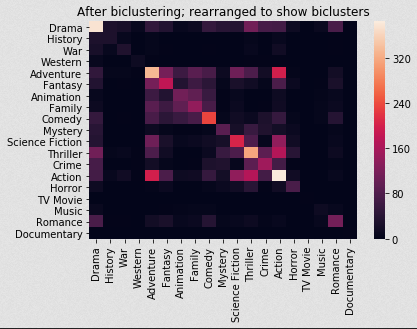
请看上图,“正方形”或者说一组电影类型自动出现了!
直观来看,犯罪,科幻,悬疑,动作,戏剧,惊悚等类型同时出现,另一方面,浪漫,科幻,家庭,音乐,冒险等类型同事出现。
这很有直观意义,对吧?
一个比较有挑战性的地方是戏剧类型具有广泛分布。它使得图中两大类集合高度重叠。如果我们使其与动作,惊悚等类型合并,那么几乎所有电影都会贴上这个标签。
根据以上内容的分析,我们可以将数据归类为“戏剧、动作、科幻、刺激(惊悚、犯罪、神秘)、振奋(冒险、幻想、动画、喜剧、浪漫、家庭)、恐怖、历史”等流派。
注意:这种分类是主观的,绝不是唯一的正确解决方案。也可以只保留原始标签,只排除那些没有足够数据的标签。这些技巧对于平衡数据集很重要,它允许我们增加或减少某些信号的强度,使得改进我们的推断成为可能:)
有趣的问题¶
在这你可以尽情发挥想象力,应该会想出一些比我更好的问题。
- 以下是一些我的想法:
- 在一些电影中,哪些演员总是演某种类型,而有些演员却不拘泥于特定类型?
- 在最近几年中是否有某种流行趋势?
- 你能用音轨来识别电影的类型吗?
- 著名的浪漫类型演员的薪水是否比著名的动作演员高?
- 如果你看上映日期和流行度得分,哪种电影类型有更长的保质期?
- 关于按种类拓展特征相关性的一些想法:
- 标题的长度是否与电影类型有关?
- 恐怖片相较于浪漫和喜剧片,电影海报是否颜色更阴暗?
- 某些类型电影是否在一年中某些特殊档期发布更多?
- RPG等级与电影类型有关么?
基于这个新的数据集,我们现在可以从TMDB抓取海报来作为我们的训练数据了!¶
# 在开始之前,我们从pickle文件中读取数据以保持数据一致性!
# 我们现在对每个类型采样100部电影。有一个问题是由于排名是按流行程度排序的,因此可能会有重复。
# 我们需要移除已经采样的那些电影。
movies = []
baseyear = 2017
print('Starting pulling movies from TMDB. If you want to debug, uncomment the print command. This will take a while, please wait...')
done_ids=[]
for g_id in nr_ids:
#print('Pulling movies for genre ID '+g_id)
baseyear -= 1
for page in xrange(1,6,1):
time.sleep(0.5)
url = 'https://api.themoviedb.org/3/discover/movie?api_key=' + api_key
url += '&language=en-US&sort_by=popularity.desc&year=' + str(baseyear)
url += '&with_genres=' + str(g_id) + '&page=' + str(page)
data = urllib2.urlopen(url).read()
dataDict = json.loads(data)
movies.extend(dataDict["results"])
done_ids.append(str(g_id))
print("Pulled movies for genres - "+','.join(done_ids))
#Pulled movies for genres - 12
现在开始从TMDB获取电影数据。如果你想调试可以将那条打印语句取消注释。这会运行一段时间,请耐心等待。。。
f6=open("movies_for_posters",'rb')
movies=pickle.load(f6)
f6.close()
让我们去除列表中那些重复数据。
movie_ids = [m['id'] for m in movies]
print "originally we had ",len(movie_ids)," movies"
movie_ids=np.unique(movie_ids)
print len(movie_ids)
seen_before=[]
no_duplicate_movies=[]
for i in range(len(movies)):
movie=movies[i]
id=movie['id']
if id in seen_before:
continue
# print "Seen before"
else:
seen_before.append(id)
no_duplicate_movies.append(movie)
print "After removing duplicates we have ",len(no_duplicate_movies), " movies"
originally we had 1670 movies 1608 After removing duplicates we have 1608 movies
同时,我们删除那些没有海报的电影!
poster_movies=[]
counter=0
movies_no_poster=[]
print("Total movies : ",len(movies))
print("Started downloading posters...")
for movie in movies:
id=movie['id']
title=movie['title']
if counter==1:
print('Downloaded first. Code is working fine. Please wait, this will take quite some time...')
if counter%300==0 and counter!=0:
print "Done with ",counter," movies!"
print "Trying to get poster for ",title
try:
grab_poster_tmdb(title)
poster_movies.append(movie)
except:
try:
time.sleep(7)
grab_poster_tmdb(title)
poster_movies.append(movie)
except:
movies_no_poster.append(movie)
counter+=1
print("Done with all the posters!")
(‘Total movies : ‘, 1670) Started downloading posters… Downloaded first. Code is working fine. Please wait, this will take quite some time… Done with 300 movies! Trying to get poster for Gravity Done with 600 movies! Trying to get poster for Zombieland Done with 900 movies! Trying to get poster for The Substitute Done with 1200 movies! Trying to get poster for Decoys Done with 1500 movies! Trying to get poster for Lost and Delirious Done with all the posters!
print len(movies_no_poster)
print len(poster_movies)
170 1500
f=open('poster_movies.pckl','r')
poster_movies=pickle.load(f)
f.close()
f=open('no_poster_movies.pckl','r')
movies_no_poster=pickle.load(f)
f.close()
恭喜,我们已经完成了信息爬取!
基于离散信息建立数据集!¶
这个任务很简单但是非常重要。基本上这将构建整个项目的基础。鉴于你可以在我提供的框架中自由构建自己的项目,你必须做出许多决定来完成你自己版本的项目。
当我们处理分类问题时,我们需要根据手头的数据做出两个决定:
- 我们想要预测什么,也就是我们的 Y 是什么?
- 我们用什么特征去预测这个 Y ,也就是我们应该用什么作为 X ?
有很多不同的选项,由你来决定什么是最好的。我将以我的版本为例,但你必须思考一下然后想出一个你认为最好的版本!
作为举例,这里有很多方式构建 Y,仍然拿类型预测问题来说:
- 假设每个电影都有多种类型,这就变成了一个多标签分类问题。比方说,一个电影可以同时是动作类,恐怖类和探险类。也就是说,每部电影可以有多个分类。
- 利用我们在第一节学到的双聚类分析生成类型组,这样每个电影就只有一个类型了。这样,问题就简化成了多类问题。比方说某个电影拥有这样的类型-刺激的,或是恐怖的,或是历史的。每个电影就只有一个分类。
为了实现这个目的,我将从上面的第一种情况开始-即多标签分类问题。
类似地,为了设计我们的输入特性,即X,您可以选择您认为有意义的任何特性,例如,电影的导演可能是流派的良好预测器。或者,他们可以选择使用PCA等算法设计的任何特性。鉴于IMDB、TMDB和维基百科等替代资源的丰富性,有很多可用的选项。这里要有创意!
另一件需要注意的重要事情是,在这样做时,我们还必须在途中做出许多更小的实现决策。例如,我们将包括哪些流派?我们要包括哪些电影?所有这些都是开放式的!
我的实现¶
实现步骤-
- 如上所述问题被简化为一个多标签问题
- 我们将尝试预测一部电影关联的多种类型,这将作为我们的Y
- 我们使用两个不同的类型作为 X – 文本和图片
- 对文本部分–被用来预测类型的输入特征使用的是电影情节,可以从TMDB获取的数据中’overview’属性得到。这将作为我们的X
- 对图片部分–我们使用爬取的电影海报图片作为我们的X
注意:我们将首先看一些传统的机器学习模型,这些模型在最近兴起的神经网络和深度学习之前很流行。对电影海报图像进行类型预测,我之所以避免使用这种方法是因为在不使用深度学习的情况下,传统的机器学习模型不再被用来特征提取(前面都详细讨论过,不要害怕术语)。对于用电影概述来预测电影类型的问题,我们将同时使用传统模型和深度学习模型。
现在,我们开始建立我们的 X 和 Y !
首先,我们筛选出那些有概述的电影。接下来的步骤是用来解释为什么数据清洗很重要的很好的案例!
movies_with_overviews=[]
for i in range(len(no_duplicate_movies)):
movie=no_duplicate_movies[i]
id=movie['id']
overview=movie['overview']
if len(overview)==0:
continue
else:
movies_with_overviews.append(movie)
len(movies_with_overviews)
1595
现在,我们把这些电影的类型存储在列表中,后面我们会把他们转化为布尔向量。
布尔向量表示法是机器学习中存储/表示数据的一种常见且重要的方法。本质上,它是将具有n个可能值的分类变量简化为n个布尔变量的一种方法。什么意思呢?比方说,[(1,3),(4)]这个列表表示样本A有两个标签1和3,而样本B有一个标签4。对每个样本来说,对于每个可能的标签,表示法简化为如果它具有该标签那么用1表示,如果没有该标签那么用0表示。上述列表的布尔表示法版本是-
[(1,0,1,0),(0,0,0,1)]
# genres=np.zeros((len(top1000_movies),3))
genres=[]
all_ids=[]
for i in range(len(movies_with_overviews)):
movie=movies_with_overviews[i]
id=movie['id']
genre_ids=movie['genre_ids']
genres.append(genre_ids)
all_ids.extend(genre_ids)
from sklearn.preprocessing import MultiLabelBinarizer
mlb=MultiLabelBinarizer()
Y=mlb.fit_transform(genres)
genres[1]
[28, 12, 35, 10749]
print Y.shape
print np.sum(Y, axis=0)
(1595, 20) [327 234 220 645 222 438 404 138 45 440 233 133 242 196 135 232 256 80 23 25]
len(list_of_genres)
19
这很有趣,如果你还记得的话,我们只有19个类型标签。但是得出 Y 的结果是 1666,20 ,而它应该是 1666,19 ,因为我们只有19个种类?我们来看看怎么回事。
让我们找出那些不属于我们原始类型列表中的类型ID!
# Create a tmdb genre object!
genres=tmdb.Genres()
# the list() method of the Genres() class returns a listing of all genres in the form of a dictionary.
list_of_genres=genres.list()['genres']
Genre_ID_to_name={}
for i in range(len(list_of_genres)):
genre_id=list_of_genres[i]['id']
genre_name=list_of_genres[i]['name']
Genre_ID_to_name[genre_id]=genre_name
for i in set(all_ids):
if i not in Genre_ID_to_name.keys():
print i
10769
这个类型ID并不是我们查询TMDB获取所有可能的类型得到的。我们现在怎么办?我们不能忽略所有包含此类型的样本。但是如果你向前看你会看到许多这样的样本。所以我google了一下又看了他们的文档发现这个ID对应的类型是’Foreign’。因此我们把它加入到我们自己定义的字典中。像这样的问题在机器学习中很常见,当我们遇到时需要调查并纠正过来。我们总是要决定哪些要保留,如何保存等等。
Genre_ID_to_name[10769]="Foreign" #Adding it to the dictionary
len(Genre_ID_to_name.keys())
20
现在我们来建立 X 矩阵也就是输入特征!之前说过,我们会使用电影概述作为我们的输入向量!我们来看一个例子!
sample_movie=movies_with_overviews[5]
sample_overview=sample_movie['overview']
sample_title=sample_movie['title']
print "The overview for the movie",sample_title," is - \n\n"
print sample_overview
The overview for the movie Doctor Strange is -
After his career is destroyed, a brilliant but arrogant surgeon gets a new lease on life when a sorcerer takes him under his wing and trains him to defend the world against evil.
我们如何在矩阵中存储电影概述?¶
我们是否就是把整个字符串存起来?我们知道我们需要数字,但这些都是文本。我们该怎么办?!
我们将使用一个称为’单词包’表速法的方法来存储X矩阵。在这里这种表示法的基本思想是我们可以把电影评论中可能出现的所有不同的单词作为不同的对象。然后每个电影的概述可以被认为是包含这些可能对象的”包”。
例如,在上文的电影疯狂动物城的例子中–单词(“determined”,”to”,”prove”,”herself”….”the”,”mystery”)组成了”包”。我们对所有电影概述列出这样的列表。最后我们用之前操作Y的方式再次进行布尔操作。我们只要简单的使用sckit-learn库提供的CountVectorizer()函数就可以了,因为这种表示法经常用于机器学习。
这意味着,对于我们拥有数据的所有电影,我们将首先计算所有唯一的单词。比如说,有30000个独特的单词。然后我们可以将每个电影概览表示为30000x1向量,其中向量中的每个位置对应于特定单词的存在或不存在。如果概览中存在与该位置对应的词,则该位置将具有1,否则为0。
例如,如果我们的词汇是4个词——”I”,”am”,”a”,”good”,”boy”,那么句子”I am a boy”的表示形式是[1 1 1 0 1],而句子”I am good”的表示形式是[1 10 1 1 0 1 0]。
from sklearn.feature_extraction.text import CountVectorizer
import re
content=[]
for i in range(len(movies_with_overviews)):
movie=movies_with_overviews[i]
id=movie['id']
overview=movie['overview']
overview=overview.replace(',','')
overview=overview.replace('.','')
content.append(overview)
print content[0]
print len(content)
A teenager finds himself transported to an island where he must help protect a group of orphans with special powers from creatures intent on destroying them 1595
是否所有单词都同等重要?¶
当我联想到”动物农场”的时候我认为不是所有的单词都同等重要。
例如,我们看下面黑客帝国中的概述-
get_movie_info_tmdb('The Matrix')['overview']
u’Set in the 22nd century, The Matrix tells the story of a computer hacker who joins a group of underground insurgents fighting the vast and powerful computers who now rule the earth.’
对于《黑客帝国》来说,像“计算机”这样的词比像“谁”、“强大”或“巨大”这样的词更能说明它是一部科幻电影。计算机科学家过去处理自然语言这一问题的一种方法(现在仍然非常普遍)就是我们称之为TF-IDF的方法,即词频、逆文本频率。这里的基本思想是,强烈说明某个文档内容的单词(在本例中,所有电影概述都是文档)是在该文档中频繁出现的单词,且在其他文档中很少出现。例如,“计算机”在这里出现两次,但在大多数其他电影概览中可能不会出现。因此,这是指示性的。另一方面,像“a”、“and”、“the”这样的泛型词在所有文档中经常出现。因此,它们不是指示性的。
那么,我们能否利用这些方法来将我们高的疯狂的30000维特征向量减少到一个更小、更易处理的大小呢?但是首先,我们为什么要这么做?答案可能是机器学习中最常用的短语之一——”维度的诅咒”。
维度的诅咒¶
这一章节参考自另一片 机器学习文章 。
这个表达式是由Bellman在1961年提出的,它指的是当输入是高维时,许多在低维下工作良好的算法变得难以处理。它们不能在高维度上工作的原因与我们前面讨论的——具有代表性的数据集密切相关。考虑这个,函数f只依赖于一个因变量x,x只能从1到100的整数值。因为它是一维的,所以它可以画在一条线上。为了获得代表性的样本,您需要对诸如-f(1)、f(20)、f(40)、f(60)、f(80)、f(100)之类的东西进行采样。
现在,让我们增加维度,即因变量的数量,看看会发生什么。比如说,我们有2个变量x1和x2,可能和前面的一样,介于1和100之间的整数。现在,不是直线,而是一个平面,两个轴上有x1和x2。有趣的一点是,我们不像以前那样有100个因变量的可能值,我们现在有100000个可能值!基本上,我们可以制作100x100的可能值x1和x2的表格。哇,这个数字成指数增长。不仅用比喻,而且用指数表示。毋庸置疑,为了像以前那样覆盖5%的空间,我们需要对f取5000个值。
对于3个变量,它将是100000000,我们需要在500000点进行采样。这已经超过了我们所遇到的大多数培训问题的数据点数。
基本上,随着示例的维度(特征数量)的增长,因为固定大小的训练集覆盖了输入空间的缩减部分。即使具有中等尺寸的100个和由数万亿个示例组成的庞大的训练集,后者也仅覆盖输入空间的大约10-18的一小部分。这就是机器学习既必要又困难的原因。
所以,是的,如果有些单词不重要,我们想去掉它们,减少X矩阵的维数。我们将采用TF-IDF识别不重要的单词。Python让我们只用一行代码来完成这个任务(这就是为什么你应该花更多的时间阅读数学而不是编码!)
# The min_df paramter makes sure we exclude words that only occur very rarely
# The default also is to exclude any words that occur in every movie description
vectorize=CountVectorizer(max_df=0.95, min_df=0.005)
X=vectorize.fit_transform(content)
我们排除了太多或太少的文件中出现的所有单词,因为这些单词不太可能具有歧视性。只出现在一个文档中的单词很可能是名称,而出现在几乎所有文档中的单词很可能是停止单词。注意,此处的值没有使用验证集进行调优。它们只是猜测。这是可以的,因为我们没有评估这些参数的性能。在严格的情况下,例如,对于发布,最好也调整它们。
X.shape
(1595, 1365)
现在,每部电影的概述由一个 1x1365 维的向量表示。
现在,我们到了最后的部分了。我们的数据已经清洗了,假设已经设置好(概述可以预测电影类型),并且特征/输出向量也准备好了。让我们开始训练一些模型吧!
import pickle
f4=open('X.pckl','wb')
f5=open('Y.pckl','wb')
pickle.dump(X,f4)
pickle.dump(Y,f5)
f6=open('Genredict.pckl','wb')
pickle.dump(Genre_ID_to_name,f6)
f4.close()
f5.close()
f6.close()
恭喜,我们的数据已经准备好了!¶
注意:由于我们正在构建自己的数据集,我不想让您把所有的时间都花在等待海报图像下载完成上,所以我正在使用一个非常小的数据集。这就是为什么,对于深度学习部分,我们将看到的结果与传统的机器学习方法相比并不引人注目。如果你想看到真正的力量,你应该多花些时间去抓取10万张图片的顺序,而不是像我这里那样抓取1000张图片。引用我上面提到的论文——MORE DATA BEATS A CLEVERER ALGORITHM。
作为助教,我看到项目中的大多数团队都有10万部电影的订单数据。因此,如果您想发挥这些模型的威力,可以考虑爬取比我更大的数据集。